Eläketurvakeskuksen koneoppimiskokeilu – näin se tehtiin!
Eläketurvakeskuksessa haluttiin selvittää, olisiko koneoppimistekniikoista hyötyä asiantuntijatyössä, erityisesti erilaisten ennusteiden ja laskelmien teossa. Testausta varten päätettiin tehdä lyhyt kokeilu yhteistyössä Siili Solutions Oyj:n datatutkija Ilkka Huopaniemen kanssa. Tässä bloggauksessa avaan projektin tuloksia ja käytettyjä menetelmiä aiheesta kiinnostuneille.
Kokeilimme koneoppimistekniikoiden käyttöä työkyvyttömyyseläkkeelle joutumisen ennustamiseen. Työkyvyttömyyseläkkeiden ennustaminen vaikutti mielenkiintoiselta projektikohteelta, koska työkyvyttömyyttä aiheuttavista tekijöistä on tehty tutkimusta jonkin verran jo entuudestaan.
Nyt painopisteenä oli ennustaminen tulevaisuuteen. Erityisesti ennusteesta tekee mielenkiintoisen se, että Eläketurvakeskuksella on pääsy laajoihin rekisteriaineistoihin kattaen lähestulkoon kaikki suomalaiset työntekijät ja eläkeläiset (ansainta- ja eläkepäätösrekisteri).
Aineistona lähes puolen miljoonan suomalaisen tiedot
Projektissa ennustettiin työkyvyttömyyden alkamista kahden vuoden kuluttua. Koneoppimisalgoritmin opetusaineisto koostui 240 000 aiemmin työkyvyttömyyseläkkeelle joutuneen henkilön anonymisoiduista sosioekonomisista-, ansio- ja sosiaalietuuksien vuositason tiedoista ajalta 2–10 vuotta ennen työkyvyttömyyseläkkeen alkamista. Verrokkeina käytettiin 240 000 satunnaisesti valittua henkilöä, jotka eivät olleet joutuneet työkyvyttömyyseläkkeelle tarkastelujakson aikana. Tästä aineistosta algoritmin oli mahdollista oppia työkyvyttömyyttä ennakoivia ilmiöitä.
Kaikesta kokeilussa käytetystä henkilötason aineistosta oli poistettu henkilöitä yksilöivät tiedot. Kaikki aineiston käsittely tehtiin Eläketurvakeskuksen käyttöympäristössä ilman pilvipalveluiden käyttöä.
Lähes 80 prosentin ennustustarkkuus
Kokeilun tuloksena selvisi, että sosioekonomisten-, ansio- ja etuustietojen avulla voidaan melko tarkasti ennustaa työkyvyttömyyseläkkeen alkaminen. Kahden vuoden kuluttua alkavista eläkkeistä pystyttiin ennustamaan oikein noin 78 prosenttia, jolloin noin 22 prosenttia jäi algoritmilta havaitsematta. Toisaalta algoritmi teki noin 20 prosenttia vääriä hälytyksiä, eli ennusti eläkkeen alkamista, vaikkei eläke todellisuudessa alkanutkaan tarkastelujaksolla.
Menetelmillä pystyttiin erityisesti tunnistamaan korkeassa riskissä olevat henkilöt ja ennustamaan näille työkyvyttömyyden alkaminen suurella tarkkuudella. Ennustustarkkuutta pystynee parantamaan vielä merkittävästi ennustusmallin jatkokehityksellä ja ottamalla käyttöön lisää aineistoja uusista lähteistä.
Eri menetelmillä samansuuntaisia tuloksia
Projektin työvälineenä käytettiin Python-ohjelmointikieltä ja siihen saatavia avoimen lähdekoodin koneoppimiseen tarkoitettuja lisäosia, erityisesti Scikit-learnia.
Jaoimme aineiston opetusaineistoon (60 % aineistosta) ja testiaineistoon (40 % aineistosta). Aineistolle tehtiin myös muuta käsittelyä, kuten liukulukujen normalisointia, kategoristen muuttujien muunnoksia dummy-muuttujiksi ja puuttuvien arvojen käsittelyä, jotka ovat tyypillistä vastaavissa koneoppimisprojekteissa.
Pyrimme ottamaan opetusaineistoon mahdollisimman tarkasti henkilöt, jotka voisivat potentiaalisesti siirtyä työkyvyttömyyseläkkeelle. Poistimme siis joukosta jo eläkkeellä olevat henkilöt, ja otimme mukaan vain 18–61-vuotiaat henkilöt. Emme myöskään ottaneet aineistoon mukaan ulkomailla asuvia.
Kokeilimme muutamia erilaisia luokitinalgoritmeja, joilla saimme hyvin samansuuntaisia ennustetuloksia:
Random forest, 77.8 % ennustetarkkuus,
- XGBoost (edistynyt päätöspuu), 77.3 % ennustetarkkuus,
- Logistinen regressio L1-regularisaatiolla, 77.0 % ennustetarkkuus
- Päätöspuu, 69 % ennustetarkkuus
- Yksinkertaiset 1-4 piilokerroksen MLP- neuroverkot, 78 % ennustustarkkuus.
Kokeilun aikana ei vielä käytetty varsinaisia aikasarjamalleja, mutta muuttujista oli käytössä vuositason aikasarjoja. Neuroverkkojen testauksessa huomasimme, että tyypillisten toimistokannettavien laskentateho ei riittänyt neuroverkkomallien läpi ajamiseen käytännöllisessä ajassa. Kokeilimme myös hieman monimutkaisempia neuroverkkoja käyttäen laskentaan Nvidian näytönohjaimella varustettua konetta, mutta nämä mallit eivät parantaneet oleellisesti neuroverkkojen ennustavuutta.
Todellisuudessa työkyvyttömyyseläkkeelle joutuvia henkilöitä on noin prosentti populaatiosta, jolloin ennustustarkkuutta on luontevaa tarkastella luokitteluvirheen sijaan ns. ”receiver operating characteristic” -käyrän avulla. Käyrästä näkee, kuinka paljon vääriä positiivisia ennusteita koneoppimisalgoritmi tekee, jotta työkyvyttömyyseläkkeelle joutuvista saadaan tietty osuus ennustettua oikein. Jos esimerkiksi keskitytään vain suurimmassa riskissä oleviin, 15 prosentin tarkkuus on jo huomattavan hyvä.
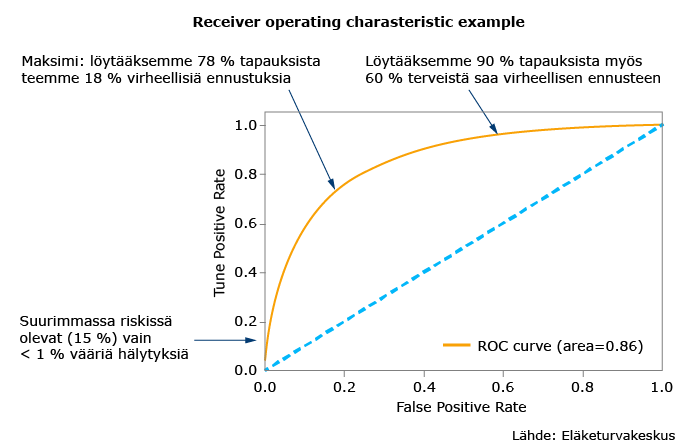
Jälkikäteisanalyysissa nähtiin, että parhaiten pystyttiin ennustamaan tuki- ja liikuntaelinsairauksista ja hengityselinsairauksista johtuvat työkyvyttömyyseläkkeet. Vaikeampaa oli ennustaa esimerkiksi mielenterveyssyistä johtuvia työkyvyttömyyseläkkeitä.
Haimme henkilöille myös tiedon onko heillä aiempia hylättyjä työkyvyttömyyseläkehakemuksia eläkepäätösrekisteristä:
| Ennuste, joutuuko ennusteajalla työkyvyttömyyseläkkeelle | Toteuma, joutuiko ennusteajalla työkyvyttömyyseläkkeelle | Osuus joilla aikaisempia hylättyjä päätöksiä |
| Ei | Ei | 0.4 % |
| Kyllä | Ei | 3.8 % |
| Ei | Kyllä | 21.4 % |
| Kyllä | Kyllä | 25.9 % |
Näyttäisi siltä, että henkilöitä, joille koneäly ennustaa työkyvyttömyyseläkettä, mutta jotka ovat saaneet vain hylätyn työkyvyttömyyspäätöksen, on suhteellisen vähän. Henkilöt, jotka saavat positiivisen työkyvyttömyyseläkepäätöksen, ovat saaneet keskimäärin enemmän hylättyjä työkyvyttömyyspäätöksiä kuin henkilöt, jotka eivät päädy työkyvyttömyyseläkkeelle. Tuloksien tulkinnassa kannattaa muistaa, että koneoppimisalgoritmi on opetettu aineistolla, jossa työkyvyttömyyseläke on päätelty hyväksytystä työkyvyttömyyseläkepäätöksestä.
Tekoäly vahvisti tutkimuksista tutut lainalaisuudet
Parhaiten työkyvyttömyyttä ennustivat korkea ikä, sairauspäivärahojen ja kuntoutusrahan runsas käyttö edeltävinä vuosina sekä ansiotulojen vähäisyys tai puuttuminen kokonaan edeltävinä vuosina. Myös matala koulutustaso, työttömyys ja naimattomuus ennustivat työkyvyttömyyseläkkeelle joutumista.
Vastaavasti korkea koulutustaso, korkeat ansiot ja avioliitto vähensivät työkyvyttömyyseläkkeen alkamisen todennäköisyyttä. Työmarkkinatuki nosti todennäköisyyttä joutua työkyvyttömyyseläkkeelle, mutta ansiosidonnainen työttömyyspäiväraha vähensi todennäköisyyttä. Liikennevakuutuksen ansiomenetyskorvaus ja tapaturmavakuutuksen ansiomenetyskorvaus lisäsivät työkyvyttömyyseläkkeen todennäköisyyttä.
Monet näistä tilastollisista riippuvuuksista tunnetaan aiemmista tutkimuksista, mutta sosioekonomisten-, ansio- ja etuustietojen käyttöä varsinaiseen henkilötason ennusteen tekemiseen ei ole aikaisemmin tehty Eläketurvakeskuksessa.
Kokeilun perusteella koneoppimistekniikat vaikuttavat potentiaaliselta apuvälineeltä asiantuntijatyön tueksi. Erityisesti tekniikalla näyttäisi pystyvän tulkitsemaan ilmiöitä, joista on paljon dataa ja paljon muuttujia, joiden avulla koneoppimismalli voidaan opettaa. Pelkästään lyhyt kokeilu työkyvyttömyyden ennustamisesta tuotti mielenkiintoisia tuloksia.
Tekoäly tunnistaa työkyvyttömyyseläkeläisen kaksi vuotta ennen eläkkeen alkamista (Tiedote 17.4.2018)
Tekoäly tunnistaa työkyvyttömyyseläkeläisen kaksi vuotta ennen eläkettä (Video 17.4.2018)

Mielenkiintoinen harjoitus. Jo ennen tulosten näkemistä olisin arvannut että logistinen regressioanalyysi toimii tähän ongelmaan varsin hyvin, niin kuin näytti toimivankin.
Toteutukseen liittyen yksi kommentti:
Hyvä tapa olisi jakaa aineisto kolmeen osaan: opetus- ja testiaineiston lisäksi tarvitaan ”validation” aineisto mallien vertailuun (esim. 60-20-20 jako). Testiaineisto olisi syytä säilyttää lopullisen mallin testaukseen, jotta tulos olisi mahdollisimman harhaton.
Logistinen regressioanalyysi tosiaan toimi tässä hyvin, siinä on hyvänä puolena että logistisen regressiomallin tulkinta onnistuu paljon paremmin kuin esim. neuroverkon.
Erittäin hyvä pointti aineiston jakamisesta myös validointiaineistoon. Käytännön syistä tässä kokeilussa teimme simppelimmän jaon. Mietimme myös käytännön validointia tulevaisuudessa, eli ennusteen tekoa rekisteriaineistosta esim. vuoden 2018 lopun tiedoista, ja sitten muutaman vuoden päästä tekisi laskelman kuinka hyvin ennustemalli käytännössä toimi.